Dual problem
In constrained optimization, it is often possible to convert the primal problem (i.e. the original form of the optimization problem) to a dual form, which is termed a dual problem. Usually dual problem refers to the Lagrangian dual problem but other dual problems are used, for example, the Wolfe dual problem and the Fenchel dual problem. The Lagrangian dual problem is obtained by forming the Lagrangian, using nonnegative Lagrangian multipliers to add the constraints to the objective function, and then solving for some primal variable values that minimize the Lagrangian. This solution gives the primal variables as functions of the Lagrange multipliers, which are called dual variables, so that the new problem is to maximize the objective function with respect to the dual variables under the derived constraints on the dual variables (including at least the nonnegativity).
The solution of the dual problem provides a lower bound to the solution of the primal problem.[1] However in general the optimal values of the primal and dual problems need not be equal. Their difference is called the duality gap. For convex optimization problems, the duality gap is zero under a constraint qualification condition. Thus, a solution to the dual problem provides a bound on the value of the solution to the primal problem; when the problem is convex and satisfies a constraint qualification, then the value of an optimal solution of the primal problem is given by the dual problem.
Contents |
Duality principle
In optimization theory, the duality principle states that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem.
In general given two dual pairs separated locally convex spaces 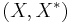 and
and 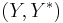 . Then given the function
. Then given the function 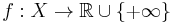 , we can define the primal problem by
, we can define the primal problem by
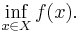
If there are constraint conditions, these can be built in to the function 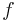 by letting
by letting 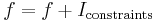 where
where 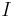 is the indicator function. Then let
is the indicator function. Then let 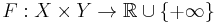 be a perturbation function such that
be a perturbation function such that 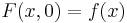 .[2]
.[2]
The duality gap is the difference of the right and left hand side of the inequality
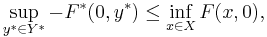
where 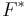 is the convex conjugate in both variables.[2][3][4]
is the convex conjugate in both variables.[2][3][4]
The linear case
Linear programming problems are optimization problems in which the objective function and the constraints are all linear. In the primal problem, the objective function is a linear combination of n variables. There are m constraints, each of which places an upper bound on a linear combination of the n variables. The goal is to maximize the value of the objective function subject to the constraints. A "solution" is a vector (a list) of n values that achieves the maximum value for the objective function.
In the dual problem, the objective function is a linear combination of the m values that are the limits in the m constraints from the primal problem. There are n "dual constraints", each of which places a lower bound on a linear combination of m "dual variables".
Relationship between the primal problem and the dual problem
In the linear case, in the primal problem, from each sub-optimal point that satisfies all the constraints, there is a direction or subspace of directions to move that increases the objective function. Moving in any such direction is said to remove "slack" between the candidate solution and one or more constraints. An "infeasible" value of the candidate solution is one that exceeds one or more of the constraints.
In the dual problem, the dual vector multiplies the constants that determine the positions of the constraints in the primal. Varying the dual vector in the dual problem is equivalent to revising the upper bounds in the primal problem. The lowest upper bound is sought. That is, the dual vector is minimized in order to remove slack between the candidate positions of the constraints and the actual optimum. An infeasible value of the dual vector is one that is too low. It sets the candidate positions of one or more of the constraints in a position that excludes the actual optimum.
This intuition is made formal by the equations in Linear programming: Duality.
Economic interpretation
If we interpret our primal LP problem as a classical "Resource Allocation" problem, its dual can be interpreted as a "Resource Valuation" problem.
The non-linear case
In non-linear programming, the constraints are not necessarily linear. Nonetheless, many of the same principles apply.
To ensure that the global maximum of a non-linear problem can be identified easily, the problem formulation often requires that the functions be convex and have compact lower level sets.
This is the significance of the Karush–Kuhn–Tucker conditions. They provide necessary conditions for identifying local optima of non-linear programming problems. There are additional conditions (constraint qualifications) that are necessary so that it will be possible to define the direction to an optimal solution. An optimal solution is one that is a local optimum, but possibly not a global optimum.
The strong Lagrangian principle: Lagrange duality
Given a nonlinear programming problem in standard form
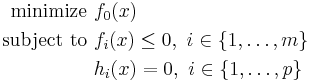
with the domain 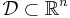 having non-empty interior, the Lagrangian function
having non-empty interior, the Lagrangian function 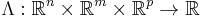 is defined as
is defined as
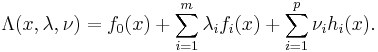
The vectors 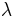 and
and 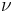 are called the dual variables or Lagrange multiplier vectors associated with the problem. The Lagrange dual function
are called the dual variables or Lagrange multiplier vectors associated with the problem. The Lagrange dual function 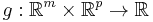 is defined as
is defined as
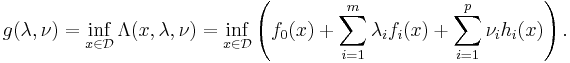
The dual function g is concave, even when the initial problem is not convex. The dual function yields lower bounds on the optimal value 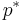 of the initial problem; for any
of the initial problem; for any 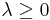 and any we have
and any we have 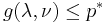 .
.
If a constraint qualification such as Slater's condition holds and the original problem is convex, then we have strong duality, i.e. 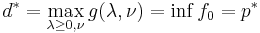 .
.
Convex problems
For a convex minimization problem with inequality constraints,
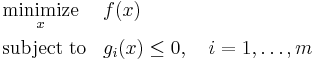
the Lagrangian dual problem is
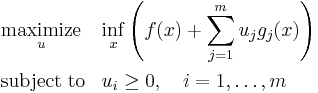
where the expression within parentheses is the Langrange dual function. Provided that the functions and  are continuously differentiable, the infimum occurs where the gradient is equal to zero. The problem
are continuously differentiable, the infimum occurs where the gradient is equal to zero. The problem
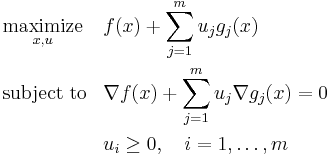
is called the Wolfe dual problem. This problem may be difficult to deal with computationally, because the objective function is not concave in 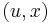 and the equality constraint
and the equality constraint 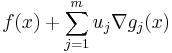 is nonlinear in general, so the Wolfe dual problem is typically a nonconvex optimization problem and weak duality holds.[5]
is nonlinear in general, so the Wolfe dual problem is typically a nonconvex optimization problem and weak duality holds.[5]
History
According to George Dantzig, the duality theorem for linear optimization was conjectured by John von Neumann, immediately after Dantzig presented the linear programming problem. Von Neumann noted that he was using information from his game theory, and conjectured that two person zero sum matrix game was equivalent to linear programming. Rigorous proofs were first published in 1948 by Albert W. Tucker and his group. (Dantzig's forward to Nering and Tucker, 1993)
See also
Notes
- ^ Boyd, Stephen P.; Vandenberghe, Lieven (2004) (pdf). Convex Optimization. Cambridge University Press. ISBN 9780521833783. http://www.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf. Retrieved October 15, 2011.
- ^ a b Radu Ioan Boţ; Gert Wanka; Sorin-Mihai Grad (2009). Duality in Vector Optimization. Springer. ISBN 9783642028854.
- ^ Ernö Robert Csetnek (2010). Overcoming the failure of the classical generalized interior-point regularity conditions in convex optimization. Applications of the duality theory to enlargements of maximal monotone operators. Logos Verlag Berlin GmbH. ISBN 9783832525033.
- ^ Zălinescu, C. (2002). Convex analysis in general vector spaces. River Edge, NJ: World Scientific Publishing Co., Inc. pp. 106–113. ISBN 981-238-067-1. MR1921556.
- ^ Geoffrion, A. M. (1971). "Duality in Nonlinear Programming: A Simplified Applications-Oriented Development". SIAM Review 13 (1): 1–37. doi:10.1137/1013001. JSTOR 2028848.
References
Books
- Ravindra K. Ahuja, Thomas L. Magnanti, and James B. Orlin (1993). Network Flows: Theory, Algorithms and Applications. Prentice Hall. ISBN 0-13-617549-X.
- Bertsekas, Dimitri P. (1999). Nonlinear Programming (2nd ed.). Athena Scientific. ISBN 1-886529-00-0.
- Bonnans, J. Frédéric; Gilbert, J. Charles; Lemaréchal, Claude; Sagastizábal, Claudia A. (2006). Numerical optimization: Theoretical and practical aspects. Universitext (Second revised ed. of translation of 1997 French ed.). Berlin: Springer-Verlag. pp. xiv+490. doi:10.1007/978-3-540-35447-5. ISBN 3-540-35445-X. MR2265882. http://www.springer.com/mathematics/applications/book/978-3-540-35445-1.
- Cook, William J.; Cunningham, William H.; Pulleyblank, William R.; Schrijver, Alexander (November 12, 1997). Combinatorial Optimization (1st ed.). John Wiley & Sons. ISBN 0-471-55894-X.
- Dantzig, G. B. (1963). Linear Programming and Extensions. Princeton, NJ: Princeton University Press.
- Hiriart-Urruty, Jean-Baptiste; Lemaréchal, Claude (1993). Convex analysis and minimization algorithms, Volume I: Fundamentals. Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]. 305. Berlin: Springer-Verlag. pp. xviii+417. ISBN 3-540-56850-6. MR1261420.
- Hiriart-Urruty, Jean-Baptiste; Lemaréchal, Claude (1993). "14 Duality for Practitioners". Convex analysis and minimization algorithms, Volume II: Advanced theory and bundle methods. Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]. 306. Berlin: Springer-Verlag. pp. xviii+346. ISBN 3-540-56852-2. MR1295240.
- Lasdon, Leon S. (2002). Optimization theory for large systems (reprint of the 1970 Macmillan ed.). Mineola, New York: Dover Publications, Inc.. pp. xiii+523. MR1888251.
- Eugene Lawler (2001). "4.5. Combinatorial Implications of Max-Flow Min-Cut Theorem, 4.6. Linear Programming Interpretation of Max-Flow Min-Cut Theorem". Combinatorial Optimization: Networks and Matroids. Dover. pp. 117–120. ISBN 0486414531.
- Lemaréchal, Claude (2001). "Lagrangian relaxation". In Michael Jünger and Denis Naddef. Computational combinatorial optimization: Papers from the Spring School held in Schloß Dagstuhl, May 15–19, 2000. Lecture Notes in Computer Science. 2241. Berlin: Springer-Verlag. pp. 112–156. doi:10.1007/3-540-45586-8_4. ISBN 3-540-42877-1. MR1900016.
- Minoux, M. (1986). Mathematical programming: Theory and algorithms (Translated by Steven Vajda from the (1983 Paris: Dunod) French ed.). Chichester: A Wiley-Interscience Publication. John Wiley & Sons, Ltd.. pp. xxviii+489. ISBN 0-471-90170-9. MR868279. (2008 Second ed., in French: Programmation mathématique: Théorie et algorithmes. Editions Tec & Doc, Paris, 2008. xxx+711 pp. ISBN-13: 978-2-7430-1000-3. MR2571910)).
- Nering, E. D.; Tucker, A. W. (1993). Linear Programming and Related Problems. Boston, MA: Academic Press.
- Papadimitriou, Christos H.; Steiglitz, Kenneth (July 1998). Combinatorial Optimization : Algorithms and Complexity (Unabridged ed.). Dover. ISBN 0-486-40258-4.
Articles
- Everett, Hugh, III (1963). "Generalized Lagrange multiplier method for solving problems of optimum allocation of resources". Operations Research 11 (3): 399–417. doi:10.1287/opre.11.3.39. JSTOR 168028. MR152360. http://or.journal.informs.org/cgi/reprint/11/3/399.
- Kiwiel, Krzysztof C.; Larsson, Torbjörn; Lindberg, P. O. (August 2007). "Lagrangian relaxation via ballstep subgradient methods". Mathematics of Operations Research 32 (3): 669–686. doi:10.1287/moor.1070.0261. MR2348241. http://mor.journal.informs.org/cgi/content/abstract/32/3/669.